Энтропия и кросс-энтропия
Энтропия
Допустим у нас есть две механических машины, которые печатают сообщения из алфавита {A, B, C, D}. Символы, печатаемые первой машиной, распределены равновероятно, то есть, появление каждого нового символа имеет вероятность 0.25:
Символы, печатаемые второй машиной, имеют иное распределение:
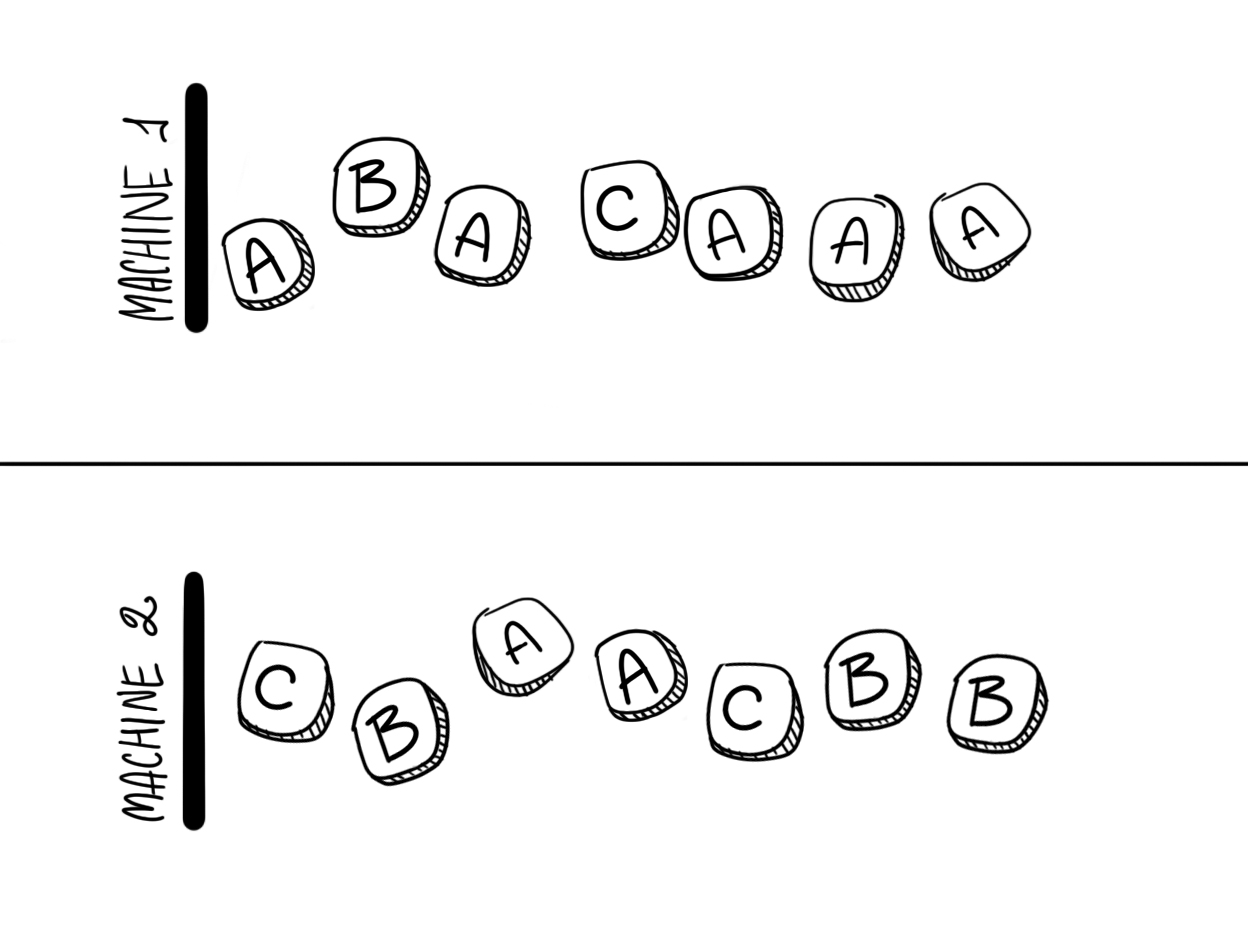
Вопрос «Какая из двух машин предоставляет нам больше информации?» или мы можем переформулировать вопрос: «Если вам необходимо предсказать следующий символ, то сколько вопросов, на которые можно ответить да или нет, потребуется задать?».
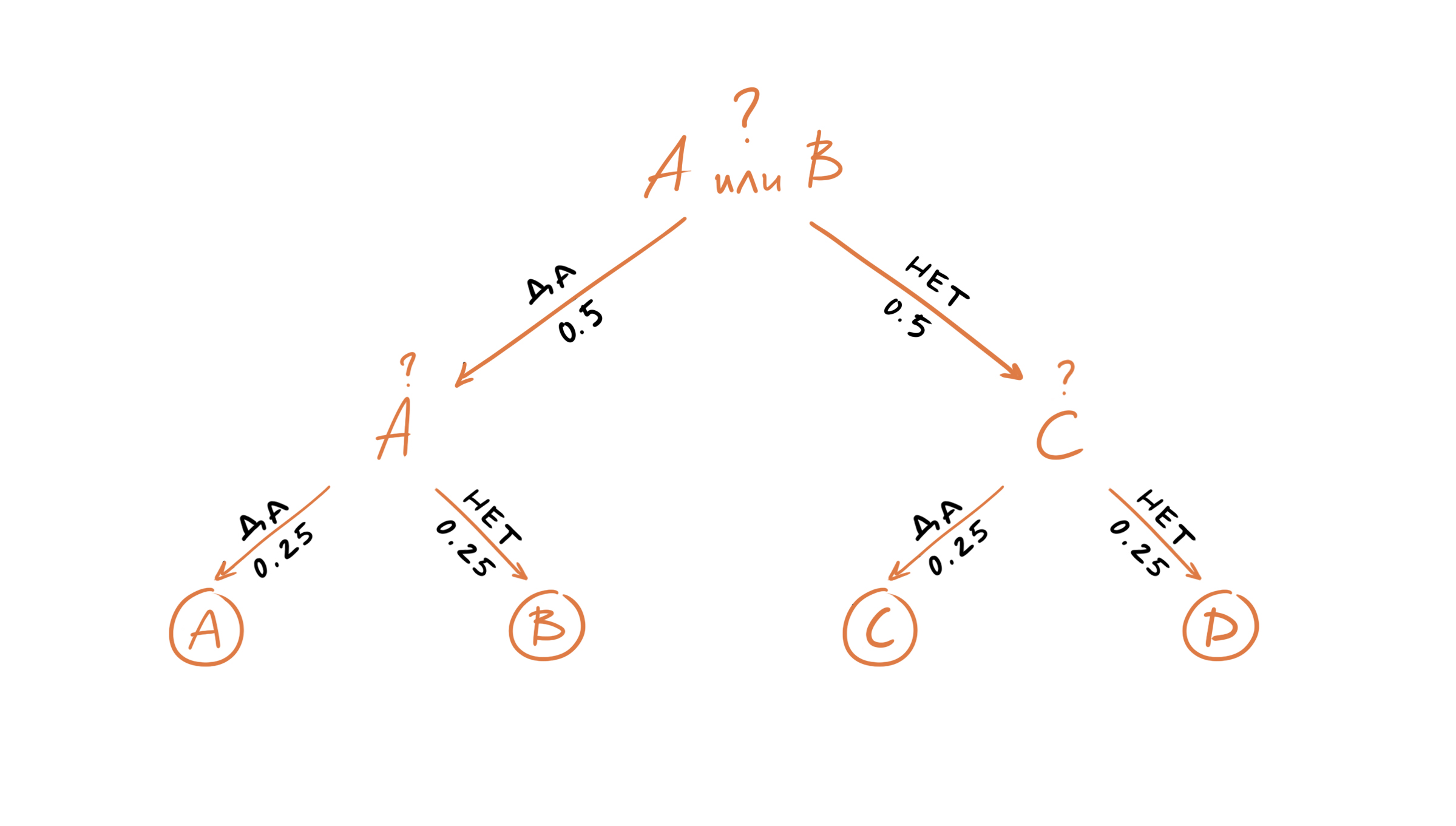
Давайте рассмотрим первую машину. Нашим первым вопросом может быть «Это символ A или B?». Так все символы появляются равновероятно, то с вероятностью 0.5 это будет «A или B» и с вероятностью 0.5 это будет «C или D». После того как мы получим ответ, нам останется задать еще один вопрос, например, «Это A?». И после того как мы получим ответ на наш последний вопрос, мы будем знать какой именно символ был следующим в последовательности, выдаваемой машиной один. Таким образом, нам достаточно двух вопросов, чтобы предсказать какой символ был сгенерирован машиной номер один.
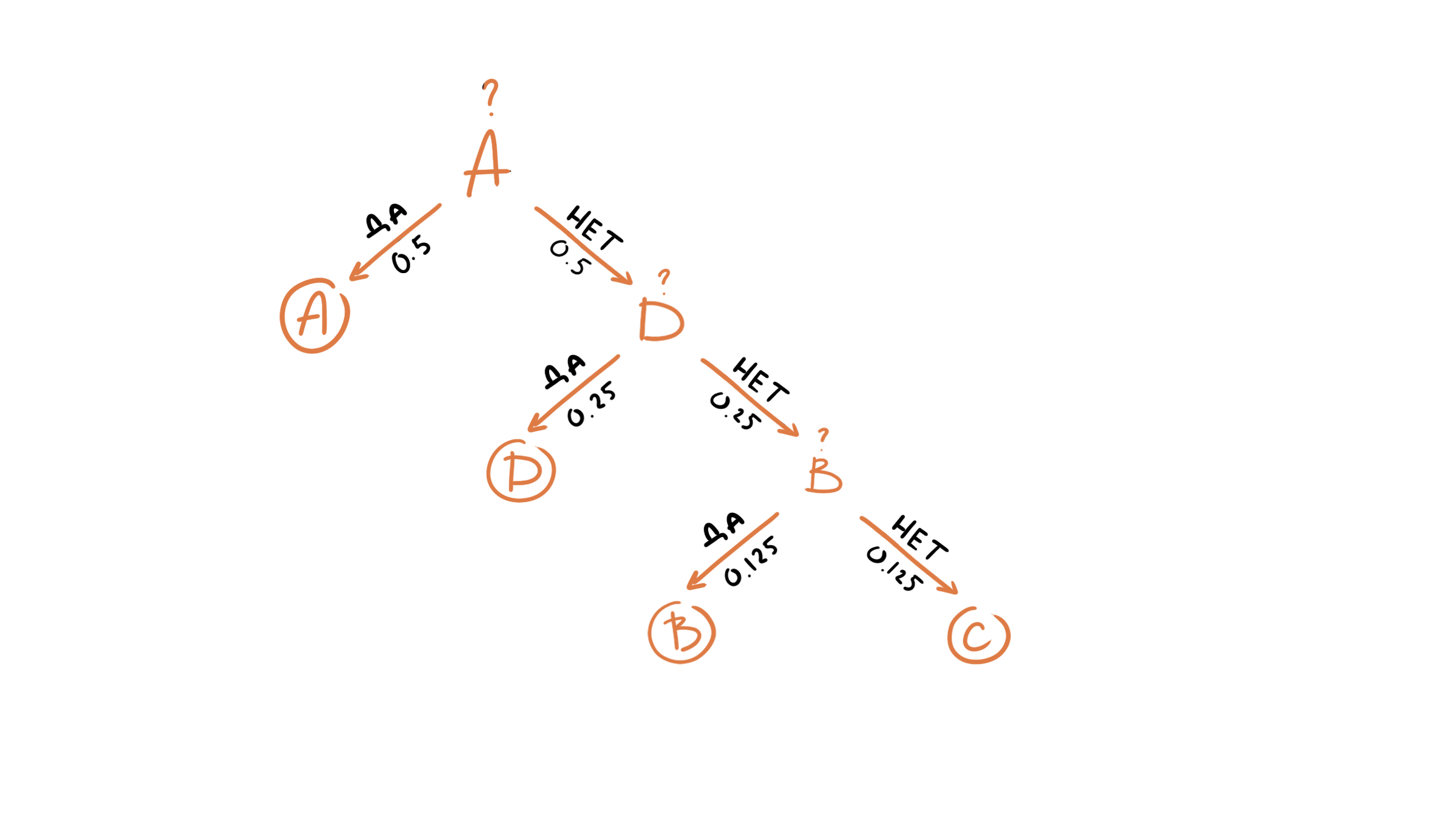
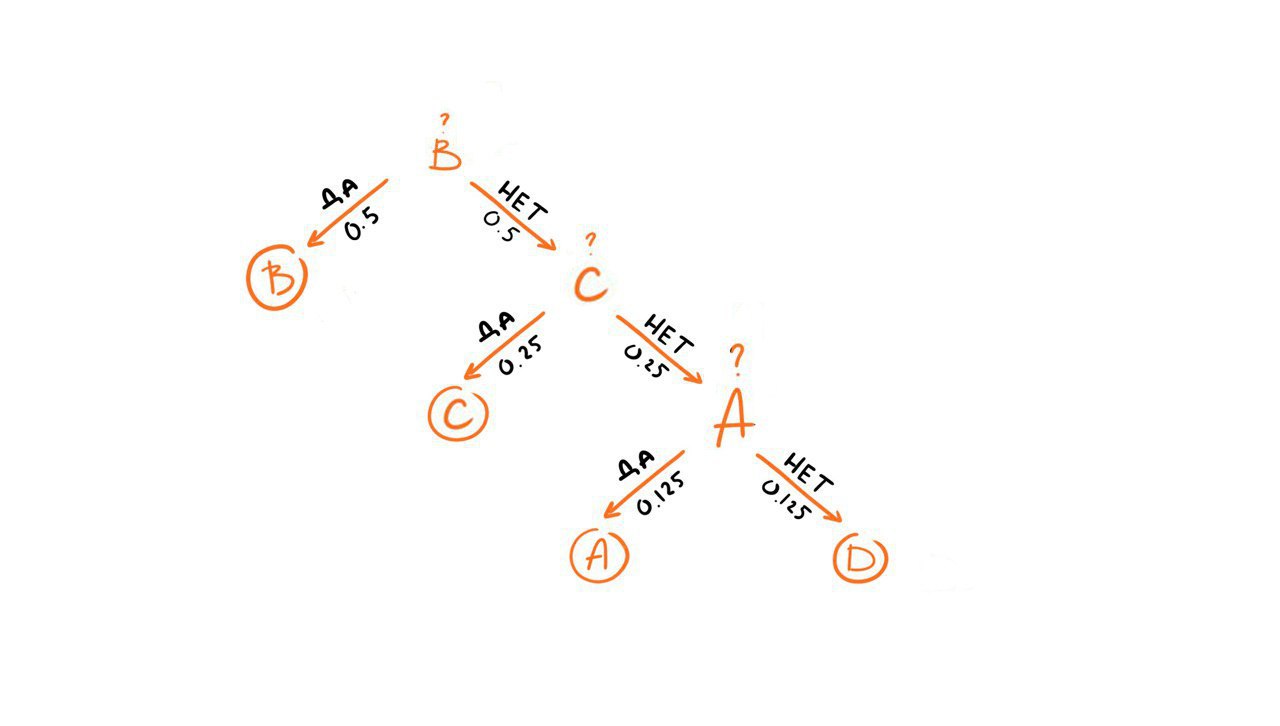
Что же касается второй машины, то мы конечно же можем задавть теже самые вопросы, но мы знаем, что у символов другое распределение, например, вероятность появления символа A равна 0.5, соответственно он будет появляться в последовательности чаще остальных символов, поэтому более разумным было бы задать первый вопрос «Это A?». Если же ответ отрицательный, то следующий символ, который имеет более высокий шанс появиться в последовательности D, поэтому следующим вопросом может быть «Это D?». Если же ответ и на этот вопрос отрицательный, то мы задаем третий и последний вопрос, например, «Это B?».
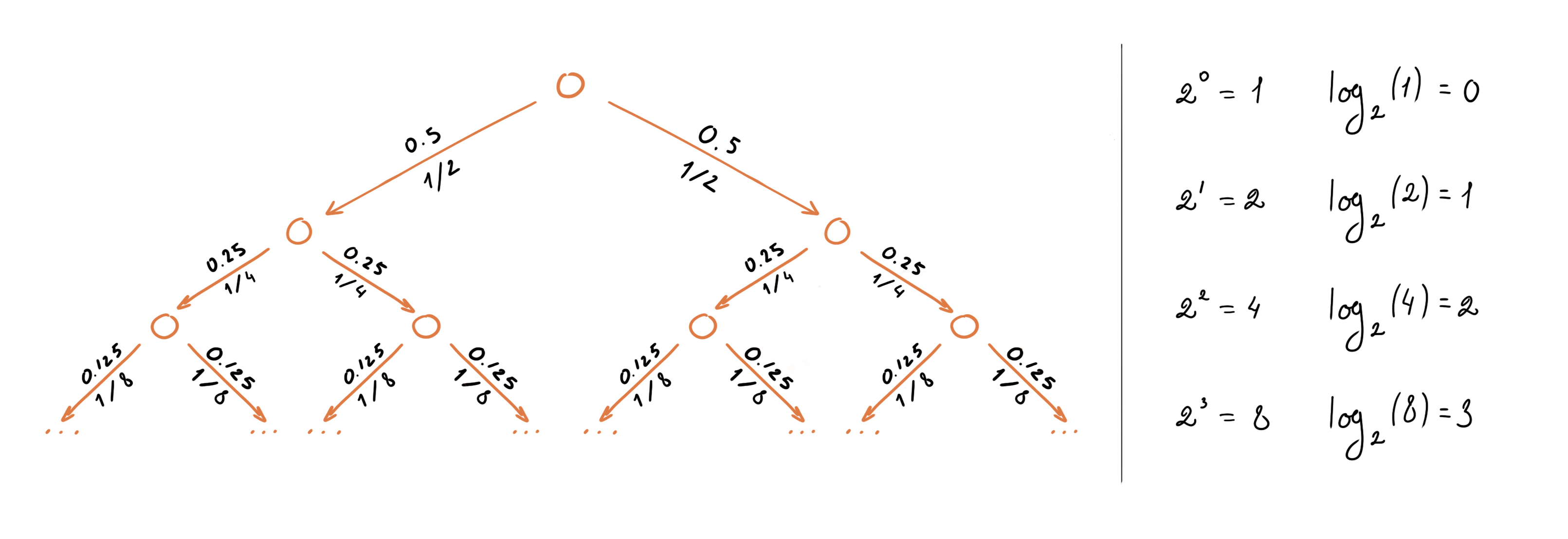
Сколько в среднем вопросов нам нужно задать, чтобы определить символ в последовательности генерируемой второй машиной?
Для этого мы можем воспользоваться формулой для вычисления математического ожидания дискретной случайной величины:
Аналогично посчитаем среднее число вопросов для первой машины:
Запишем в общем виде:
Где:
Окончательно можем записать формулу для вычисления энтропии как:
Кросс-энтропия
Давайте предположим, что у нас есть еще одна машина, которая генерирует теже символы, но с другим распределением:
Что произойдет, если вы будете задавать вопросы опираясь на распределение первой машины, несмотря на то, что символы были сгенерированы второй машиной, которая имеет иное распределение (и наоборот). Давайте оценим среднее число вопросов в этом случае, для этого воспользуемся формулой перекрестной энтропии (cross-entropy):
Чтобы посчитать сколько информации будет потеряно, когда мы аппроксимируем одно распределение другим, можно использовать «расстояние» Кульбака-Лейблера (KL divergence):
Для нашего примера получим:
Кросс-энтропия как функция потерь
Логистическая функция потерь (binary cross-entropy):